
2080亿晶体管、1700W功耗!老黄抛出了真正的战术核弹

黄仁勋正式拿出了新一代Blackwell GPU架构,以及基于此的B100/B200 GPU芯片、GB200超级芯片、DGX超级计算机,再次将“战术核弹”提升了全新的境界,傲视全球。

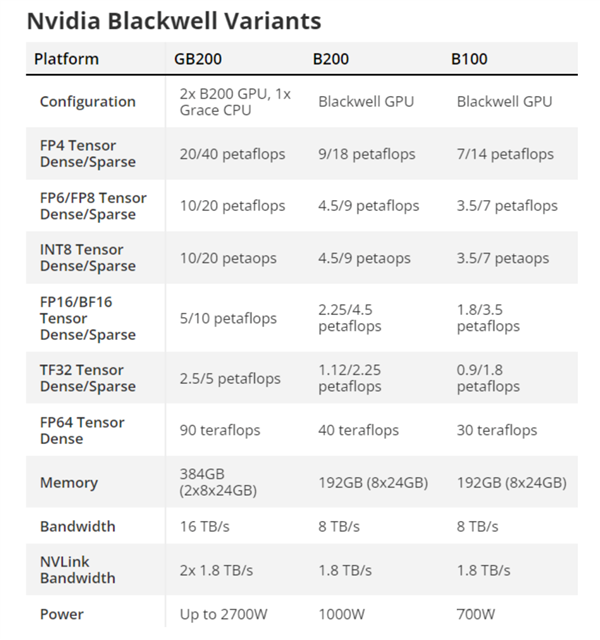
Blackwell B200 GPU首次采用了chiplet晶粒封装,包含两颗B100,而B200之间再通过带宽翻倍达1.8TB/s的第五代NVLink 5总线互连,最多可连接576块。
B100采用专门定制的台积电4NP工艺制造(H100/RTX 40 4N工艺的增强版),已经达到双倍光刻极限尺寸,彼此通过10TB/s带宽的片间互联带宽,连接成一块统一的B200 GPU。
B100集成多达1040亿个晶体管,比上代H100 800亿个增加了足足30%,B200整体就是2080亿个晶体管。
核心面积未公布,考虑到工艺极限应该不会比814平方毫米的H100大太多。
CUDA核心数量也没说,但肯定会大大超过H100 16896个,不知道能不能突破2万个?
每颗B100连接四颗24GB HBM3E显存/内存,等效频率8GHz,位宽4096-bit,带宽达4TB/s。
如此一来,B200就有多达192GB HBM3E,总位宽8096-bit,总带宽8TB/s,相比H100分别增加1.4倍、58%、1.4倍。

性能方面,B200新增支持FP4 Tensor数据格式,性能达到9PFlops(每秒9千万亿次),INT/FP8、FP16、TF32 Tensor性能分别达到4.5、2.25、1.1PFlops,分别提升1.2倍、1.3倍、1.3倍,但是FP64 Tensor性能反而下降了40%(依赖GB200),FP32、FP64 Vector性能则未公布。
Blackwell GPU还支持第二代Transformer引擎,支持全新的微张量缩放,在搭配TensorRT-LLM、NeMo Megatron框架中的先进动态范围管理算法,从而在新型4位浮点AI推理能力下实现算力和模型大小的翻倍。
其他还有RAS可靠性专用引擎、安全AI、解压缩引擎等。
至于功耗,B100控制在700W,和上代H100完全一致,B200则首次达到了1000W。
NVIDIA宣称,Blackwell GPU能够在10万亿参数的大模型上实现AI训练和实时大语言模型推理。
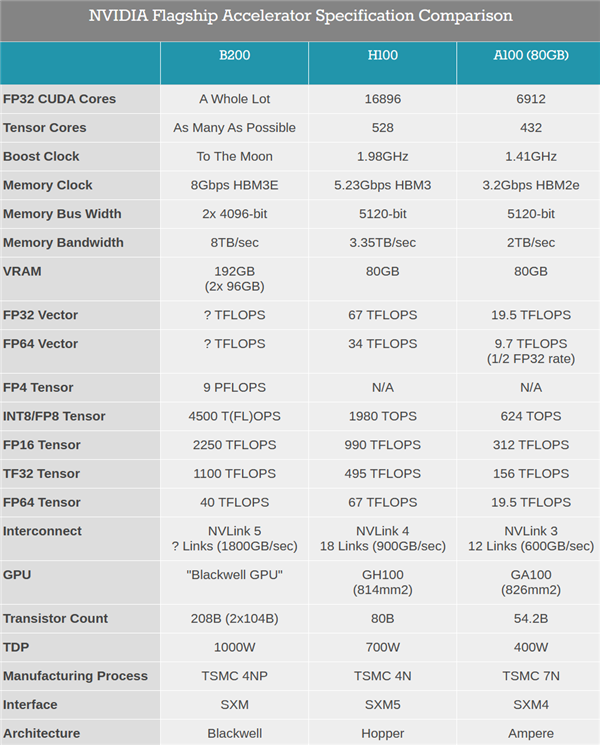
GB200 Grace Blackwell是继Grace Hopper之后的新一代超级芯片(Superchip),从单颗GPU+单颗CPU升级为两颗GPU加一颗CPU,其中GPU部分就是B200,CPU部分不变还是Grace,彼此通过900GB/s的带宽实现超低功耗片间互联。
在大语言模型推理工作负载方面,GB200超级芯片的性能对比H100提升了多达30倍。
不过代价也很大,GB200的功耗最高可达2700W,可以使用分冷,更推荐使用液冷。

基于GB200超级芯片,NVIDIA打造了新一代的AI超级计算机“DGX SuperPOD”,配备36块超级芯片,也就是包含36颗Grace CPU、72颗B200 GPU,彼此通过NVLink 5组合在一起,还有多达240TB HBM3E。
这台AI超级计算机可以处理万亿参数的大模型,能保证超大规模生成式AI训练和推理工作负载的持续运行,FP4精度下的性能高达11.5EFlops(每秒1150亿亿次)。
DGX SuperPOD还具有极强的扩展性,可通过Quantum-X800 InfiniBand网络连接,扩展到数万颗GB200超级芯片,并加入BlueField-3 DPU数据处理单元,而每颗GPU都能获得1.8TB/s的高带宽。
第四代可扩展分层聚合和规约协议(SHARP)技术,可提供14.4TFlops的网络计算能力,比上代提升4倍。

此外,NVIDIA还发布了第六代通用AI超级计算平台“DGX B200”,包含两颗Intel五代至强处理器、八颗B200 GPU,具备1.4TB HBM3E、64TB/s带宽,FP4精度性能144PFlops(每秒14亿亿次),万亿参数模型实时推理速度提升15倍。
DGX B200系统还集成八个NVIDIA ConnectX-7网卡、两个BlueField-3 DPU高性能网络,每个连接带宽高达400Gb/s,可通过Quantum-2 InfiniBand、Spectrum?-X以太网网络平台,扩展支持更高的AI性能。

基于Blackwell GPU的产品将在今年晚些时候陆续上市,亚马逊云、戴尔、谷歌、Meta、微软、OpenAI、甲骨文、特斯拉、xAI等都会采纳。
亚马逊云、谷歌云、微软Azeure、甲骨文云将是首批提供Blackwell GPU驱动实例的云服务提供商,NVIDIA云合作伙伴计划的中的Applied Digital、CoreWeave、Crusoe、IBM Cloud、Lambda也将提供上述服务。
Indosat Ooredoo Hutchinson、Nebius、Nexgen Cloud、甲骨文欧盟主权云、甲骨文美国/英国/澳大利亚政府云、Scaleway、新加坡电信、Northern Data Group旗下的Taiga Cloud、Yotta Data Services旗下的Shakti Cloud、YTL Power International 等主权AI云,也将提供基于Blackwell架构的云服务和基础设施。


AI新时代不但对算力、模型要求越来越高,也需要越来越强大的网络。为此,NVIDIA发布了专为大规模AI量身订制的全新网络交换机——X800系列。
据悉,NVIDIA Quantum-X800 InfiniBand网络、Spectrum-X800以太网络是全球首批高达800Gbps端到端吞吐量的网络平台,早期用户包括微软Azure、甲骨文云、Coreweave等等。
Quantum-X800平台可以说是AI专用基础设施极致性能的新标杆,包含Quantum Q3400交换机、ConnectX-8 SuperNIC网卡,二者互连的端到端吞吐量达到了业界领先的800Gbps(80万兆)。
同时,交换带宽容量比上一代提高5倍,网络计算能力则凭借NVIDIA SHARPv4技术提高9倍,达到了14.4TFlops,也就是每秒14.4万亿次计算。
Spectrum-X800则包含Spectrum SN5600交换机、BlueField-3 SuperNIC网卡,吞吐量同样高达800Gbps,可为多租户AIGC云和大型企业级用户提供各种至关重要的先进功能。
软件方面,NVIDIA 提供面向万亿参数级AI模型性能优化的网络加速通信库、软件开发套件、管理软件等全套软件方案。
其中,NVIDIA集合通信库(NCCL)可将GPU的并行计算任务扩展到Quantum-X800网络,并利用基于SHARPv4的强大网络计算能力、对FP8数据格式的支持,为大模型训练和AIGC提供超强的性能。
全球多家头部基础设施供应商和系统厂商将从2025年开始,提供基于Quantum-X800、Spectrum-X800的网络平台,包括Aivres、DDN、戴尔、Eviden、Hitachi Vantara(日立旗下)、慧与、联想、超微、VAST Data等等。

汽车方面,NVIDIA宣布,今年初发布的新一代汽车超级芯片/车载计算平台DRIVE Thor又赢得了更多客户的青睐,包括中国的五家大型车企。
DRIVE Thor(雷神)是专为汽车行业日益重要的生成式AI应用而打造的车载计算平台,是上代DRIVE Orin的升级版,将所有功能整合在同一个集中式平台上。
它可提供丰富的座舱功能、安全可靠的高度自动化驾驶和无人驾驶功能,广泛适用于新能源汽车、卡车、自动驾驶出租车、自动驾驶公交车、无人配送车等。
DRIVE Thor芯片的具体技术细节公布得不多,此前只知道770亿晶体管,Grace CPU联合Hopper/Ada GPU,支持FP8数据格式,浮点性能高达2PFlops,八倍于Orin。
不过按照黄仁勋的最新说法,DRIVE Thor其实也升级到了Blackwell架构的GPU,专为Transformer、LLM、AIGC工作负载而打造,看起来之前是不方便公开。
DRIVE Thor预计最早将于明年开始量产。

新能源汽车客户方面,除了理想、极氪已宣布引入DRIVE Thor,还新增了三家中国车企:
比亚迪:
不但在DRIVE Thor上构建下一代电动车型,还计划将NVIDIA AI基础设施用于云端AI开发和训练技术,并使用NVIDIA Isaac与NVIDIA Omniverse平台,开发用于虚拟工厂规划和零售配置器的工具与应用。
广汽埃安昊铂:
下一代电动汽车将采用DRIVE Thor平台,2025年开始量产,可实现L4级自动驾驶。
目前的旗舰车型昊铂GT搭载了DRIVE Orin,支持L2+级高速自动驾驶。
小鹏:
将把DRIVE Thor平台作为其下一代电动汽车的“AI大脑”,搭配小鹏汽车自研的XNGP智能辅助驾驶系统,可实现自动驾驶和泊车、驾乘人员监控等功能。
此外,文远知行正与联想车计算合作,基于DRIVE Thor平台打造多个商用L4级自动驾驶解决方案。
该方案将集成于联想的首款自动驾驶域控制器AD1,用于各种以城市为中心的用例,具备功能安全、冗余安全设计、融合可扩展等技术特点。
